
Confluent Moves to Close the Gap Where Enterprise AI Projects Quietly Die
Most enterprise artificial intelligence projects do not fail because the model is wrong, and they do not fail in front of customers; they fail much earlier and much more quietly, somewhere in the plumbing, where the data meant to feed the model turns out to be stale, exposed, or locked behind a wall the security team refuses to open. It is precisely this unglamorous stretch of the AI life cycle that Confluent set out to address with a set of capabilities announced on 19 May across Confluent Intelligence and Confluent Cloud.
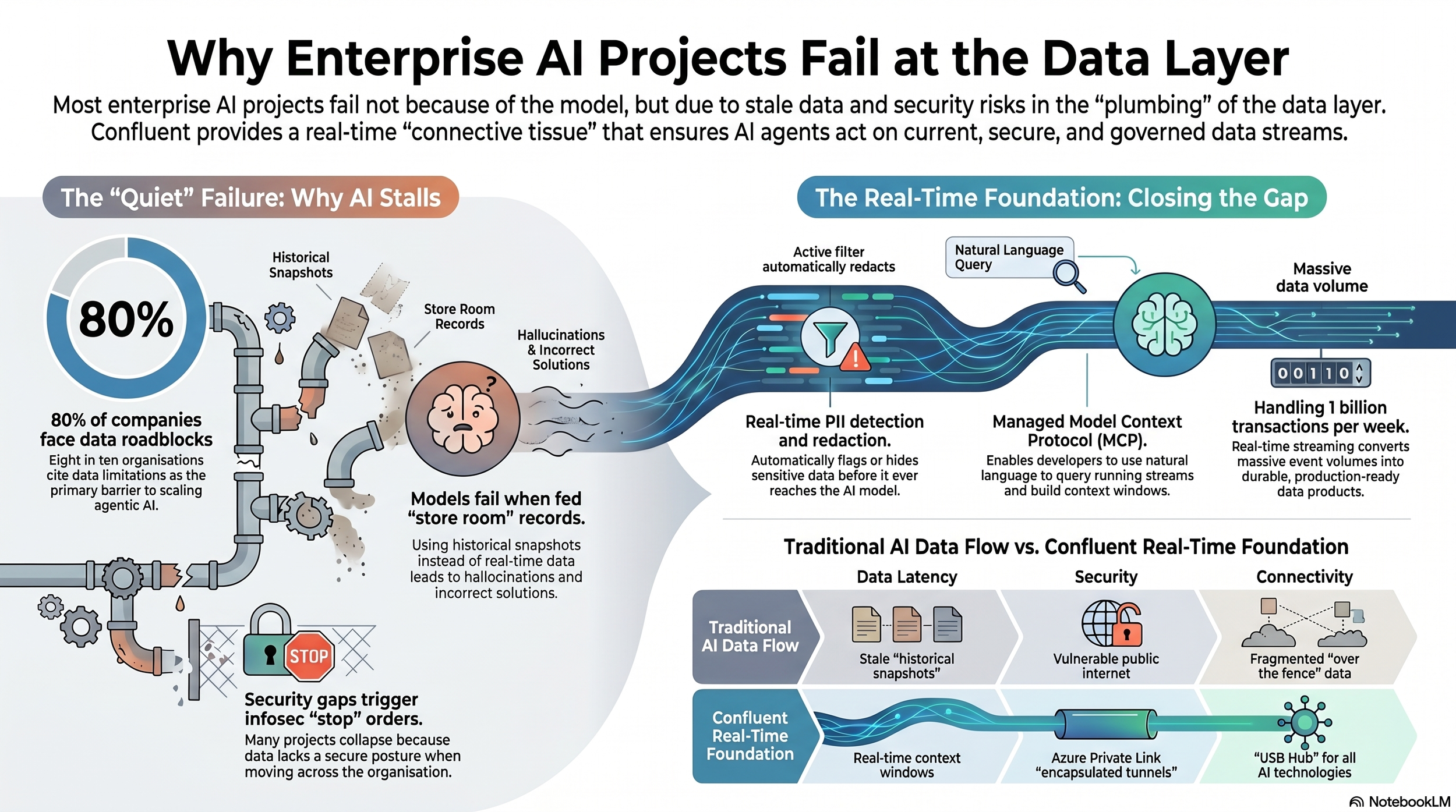
The company, now an IBM company and long known as the data streaming pioneer, positioned the updates as a direct response to the reasons AI workloads stall on their way to production. The release introduced a fully managed Model Context Protocol server, automated detection and redaction of personally identifiable information inside the data streams themselves, and private cloud connectivity through Azure Private Link, each mapped to a specific point where deployments tend to break down.
The scale of the problem is not anecdotal. Confluent pointed to a McKinsey report finding that eight in ten companies cite data limitations as a roadblock to scaling agentic AI, a figure that shifts the conversation away from model quality and towards the more mundane question of whether an organisation can move its data safely and quickly enough for an agent to act on it.
Sean Falconer, Head of AI at Confluent, said the failures begin well before deployment. “Most AI projects fail before they reach a single customer because the data layer breaks down,” he said, adding that teams have the models and the mandate but that security risks and fragmented data stop them from shipping, and that the company was fixing that by making the streaming layer the foundation for secure, production-ready AI.
The boundary between data streaming and AI infrastructure is dissolving, and Confluent wants to be what holds the two together
Steve Fernandes, Director of Solutions Engineering for the Middle East at Confluent, explained that Confluent Intelligence began as a suite of three products built around the company’s data streaming heritage. There was a real-time context engine that supplies context to an AI solution at the moment a model needs it, streaming agents that operate on data as it arrives rather than on historical snapshots, and built-in machine learning functions that draw on third-party models for prediction and classification rather than on anything Confluent builds itself.
The latest release added to each of those components, and Fernandes described the managed Model Context Protocol server as the piece that brings the platform closest to the developer. “With natural language capability, which is the MCP server, you can actually talk to it and just say hey I want to spin up a cluster, I want to tear down something, or I want to investigate the metrics, purely in natural language,” he said, describing a control surface meant to remove the steep operational learning curve.
That same server, he explained, lets an agent query a running stream and assemble a working context window on the spot. “If a stream’s running, let’s say there’s transactions happening in real time and an agent needs to look up the last five transactions,” he said, the server can build a context window and populate those transactions into a table the agent can read and act on, a capability that only matters if the underlying data is genuinely current.
On the larger question of where data streaming ends and AI infrastructure begins, he was unambiguous. “I think those boundaries are getting dissolved personally,” he said. The older pattern of moving data from one place to another, throwing it over the fence into an AI system and waiting for a result, no longer holds in an agentic world, because agents need to act on the freshest possible data.
Confluent’s ambition, he added, is to be the layer that carries whatever comes next. “Confluent wants to actually be that central nervous system, or that connective tissue I would say, to whatever new technology gets thrown out there,” he said, so that customers can stay close to the source and react in milliseconds, whether the use case is fraud or anomaly detection.
Customers already streaming in real time are, in his phrase, two steps ahead, and the failed pilots elsewhere show why
The competitive argument Fernandes made rested less on the new features than on the foundation beneath them. “I think we are two steps ahead,” he said of Confluent customers, because their data foundation is already set up for real time, which leaves those organisations ready to initiate use cases such as anomaly detection and fraud monitoring of the sort already running across financial institutions and manufacturing.
He was openly puzzled by vendors talking about real-time data without having built for it, suggesting they faced a heavy lift, and he tied the wider wave of failed pilots back to the same root cause. A strong real-time data foundation, he noted, has shifted from a good-to-have to something close to mandatory as agentic systems take hold.
The analogy he reached for was an office where every worker is handed a task but sent to the store room to consult old records. “If it’s constantly being updated and they’re seeing the latest information, those agents are going to act and give more correct answers and solutions and less hallucination,” he said, holding the absence of a live foundation, more than any shortfall in the models, responsible for so many stalled projects.
Security formed the second half of his diagnosis, and he was direct that a significant share of failed proofs of concept collapse not on data readiness but on an inadequate security posture. “Many infosec teams are halting and stopping projects because you’re letting data fly across your organisation with no security posture behind it,” he said.
Confluent’s response runs along two lines. The PII detection and redaction now baked into Confluent Intelligence can flag, hide, or redact a credit card number, medical identifier, or social security number in real time before it reaches an AI model, alerting a compliance team or pausing a job in the process. Support for Azure Private Link adds a second layer, which Fernandes described as “this encapsulated tunnel” that lets data reach external models without traversing the public internet.
He was candid that Confluent does not consider itself the security specialist in the room, working instead alongside the cloud providers and adapting its technology to fit within their constraints. “We are already looking ahead as to security trends, and that’s also what kind of drives our roadmap,” he said, noting that the company tracks the security plans of Azure, AWS, and Google Cloud closely enough to begin development before a new method ships.
Adoption splits cleanly into three groups, and the bottleneck is rarely the technology
Asked where the market actually sits on real-time AI architecture, Fernandes resisted a single answer and sorted customers into three groups. There are the digital-native organisations with strong data foundations and a firm grasp of their tooling, for whom adoption is fast, a middle tier sitting at an inflection point and unsure how to proceed, and those who have not yet begun to build a data foundation or governance structure at all.
For that third group, the work starts well before any discussion of AI. “We have to conduct kind of maturity assessments within organisations, because sometimes it’s not even the technology that’s the bottleneck,” he said, “it’s actually the organisation, the culture.” His standing advice was to take two steps back and read the adoption curve from there, since a technically capable team held back by its own organisation will adopt nothing regardless of the tools available to it.
The scalability question drew the most concrete answer of the conversation, and rather than offer a hypothetical Fernandes pointed to live deployments in the region. “In the region, the financial customers that we have, you’re talking about a billion transactions in a week,” he said, stressing that he had verified the figure by sitting with it directly. “I’m not messing with that, because I’ve actually sat there and seen it.”
A billion transactions, he noted, are merely events that happened and disappeared unless an organisation can extract insight from them in real time, feeding downstream analytics and AI applications, updating models on live card-transaction data, and driving customer hyper-personalisation as it happens. “That’s what Kafka was built for,” he said. “It was built for massive throughput and massive amounts of transactions,” converting fleeting events into durable data products that downstream applications can consume.
On the roadmap, his rule of thumb is that most of the noise is just noise
Looking ahead, Fernandes applied a deliberately sceptical filter to the pace of change. “I think it’s 80% noise, 20% actual true innovation,” he said of what he was seeing come to market, and he located Confluent’s durability in its refusal to chase the next model or build a rival to the prevailing chatbots.
The company intends to remain the connective tissue, a layer that holds firm regardless of which technology arrives next, on the condition that real-time data remains the foundation those technologies depend on. “This connective tissue holds strong irrespective of the technology that comes out,” he said, because as long as data is the foundation, Confluent stays relevant.
He pointed to the rise of natural-language and agent-driven coding tools as a case already covered, since a developer can now instruct such a tool to build a Kafka cluster and the managed MCP server is ready to receive that instruction. “We are like the USB hub, where everything can come and stick into Confluent,” he said, citing the data lakehouse platforms such as Databricks and Snowflake the company already ingests into, and the open table formats it supports as part of keeping step with modern data architecture.
As long as Confluent stays in tow with those architectures and looks ahead to any trajectory that requires data as its foundation, he concluded, the platform would remain at par with whatever emerged. It is a position that returns the announcement to the single idea running beneath it, that the model is rarely the hard part and the data almost always is.