
Everpure bets its roadmap on data primacy, sequencing every release around one path to production AI
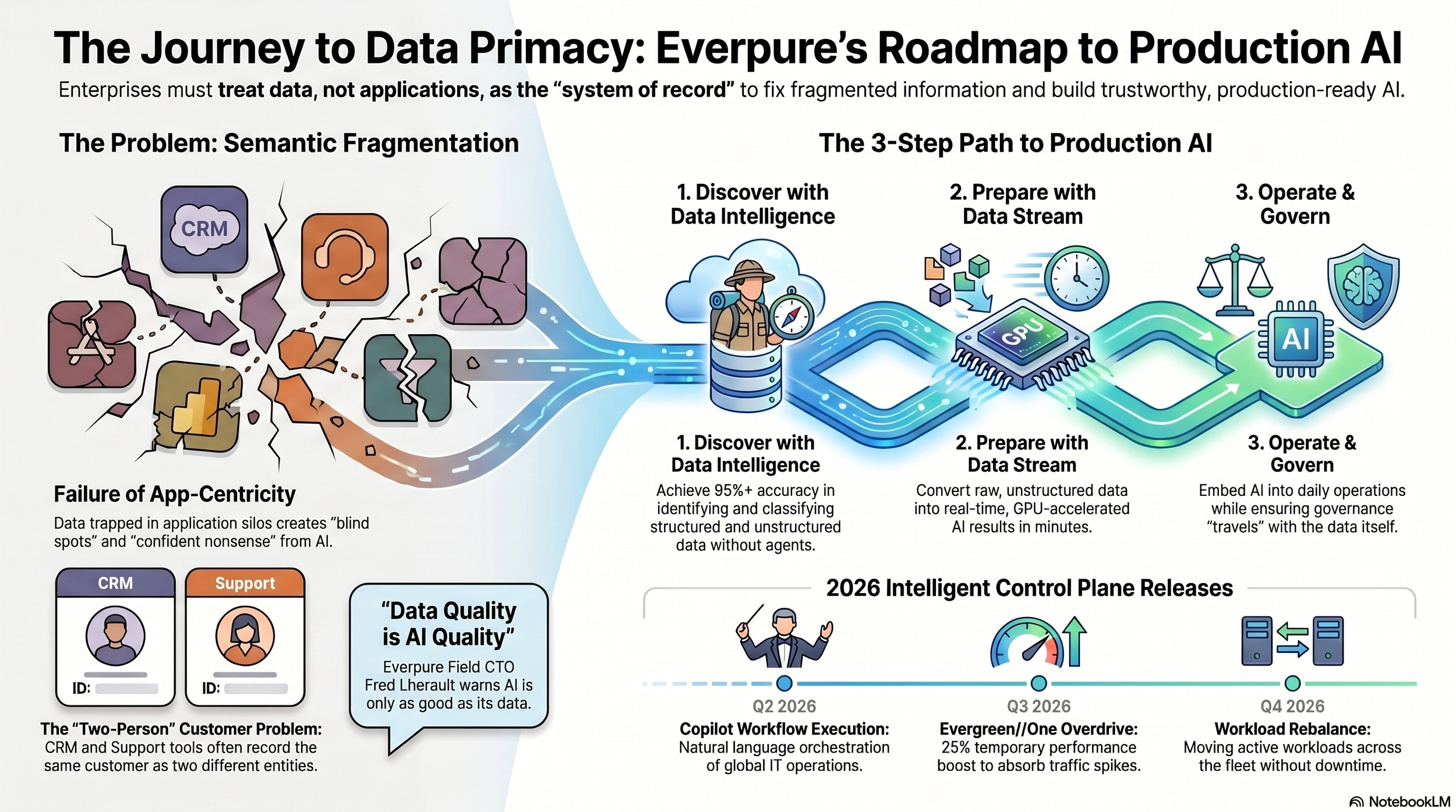
Inside most large enterprises the same customer is logged as two different people, one record living in the sales team’s CRM and another in the support tool, and neither system knows the other exists. Repeated across every application a business runs, that fracture is the reason artificial intelligence so often produces confident nonsense, and it is the problem Everpure set out to answer at its Accelerate 2026 conference, where the company recast a year of disparate product announcements into a single argument about treating data, rather than applications, as the foundation on which everything else is built.
The announcements themselves were substantial: the introduction of Everpure Data Intelligence, the general availability of Data Stream, and a series of Enterprise Data Cloud updates. What tied them together was a claim that the fix for that fracture is to make data itself the primary asset around which everything else is built. Charles Giancarlo, Chairman and Chief Executive Officer of Everpure, set the terms directly. “AI completely upends the traditional IT hierarchy; enterprises that do not shift from app-centricity to data primacy will fall behind,” he said. The company’s account of the problem rests on the observation that critical information and its context have historically been trapped inside application silos built for discrete functions such as sales, finance, or logistics, an arrangement that now produces data sprawl, blind spots, and costly replication of information no one fully trusts.
That diagnosis determines the shape of everything Everpure announced. Rather than a list of features, the company laid out a sequence in which each release answers a distinct stage of one problem. An organisation cannot prepare data for AI until it understands what data it holds, cannot run AI at scale until that data has been converted into a usable form, and cannot trust the results until governance is attached to the information itself rather than policed by software sitting outside it. The roadmap follows that order, and so does the story of how Everpure intends to sell it.
You cannot govern data you cannot see
Discovery comes first, anchored by Everpure Data Intelligence, the renamed product the company acquired as 1touch.io. Fred Lherault, Field CTO EMEA/Emerging at Everpure, described the underlying condition as semantic fragmentation, where the same entity is recorded differently across disparate systems, and no single source reconciles them. He had set out the problem plainly in a pre-briefing ahead of the conference. “A customer means something different if you’re looking at the CRM used by the sales team than if you’re looking at the support tool that they’re using,” he said, “but really they’re the same customer.” The arrival of artificial intelligence, in his account, threatens to deepen the very problem it is meant to solve. “With an AI assistant, anyone can create an application, and that application has its own data set,” he added. “So now you’ve even more fragmented the data landscape.”
Data Intelligence is built to work against that drift. It operates on data wherever it resides, spanning the Everpure platform, public clouds, SaaS applications, mainframes, and third-party storage, and it does so without agents. Lherault singled out mainframe comprehension as a particular differentiator, warning that partial visibility is no visibility at all. “Until you have a full view of the data wherever it is, on prem, in the cloud, in SaaS, in mainframe, you actually don’t understand all of the data,” he said. The product delivers three capabilities across the estate: universal discovery of structured and unstructured data regardless of format, automated governance that identifies sensitive information such as PII and PHI while tracking lineage, and AI-ready context that maps raw data to its real-world business definition to build a semantic knowledge graph.
A reasonable objection is that enterprises have been promised data cleanliness for more than a decade, and Lherault met it head-on when pressed on what has actually changed. The gap, he said, came down to three things: the speed of analysis, the accuracy achievable out of the box, and the fact that data is more fragmented than ever despite years of industry attempts to consolidate it into lakes and warehouses. Manual classification by human analysts was too slow and too error-prone to keep pace, whereas Data Intelligence detects and classifies with accuracy above 95% before any human tuning, leaving people to handle only the final adjustments.

Fred Lherault, Field CTO EMEA/Emerging at Everpure
Finding the data is only half the work
Knowing what an organisation holds is not the same as making that data ready for a model to consume, and the second stage closes that gap with the general availability of Everpure Data Stream. The platform extends the NVIDIA AI Data Platform reference design into a pipeline that converts unstructured data into real-time AI results, replacing manual ingestion and manipulation with a GPU-accelerated path from ingestion through to inference. The company claims the approach reduces raw data preparation from months to minutes while enforcing stream-level access controls that keep information inside the corporate network.
Lherault placed Data Stream as the step that follows discovery rather than a parallel offering. Once an organisation has located its data, he explained, the task becomes “creating pipelines to vectorize it and get to the point where it’s been enriched and it can be consumed by AI directly,” after which models can run for training or, more commonly, for inference on AI-ready infrastructure. Robert Lee, Chief Technology Officer of Everpure, situated the release within a broader market dynamic. “We are undergoing a massive capital supercycle in AI, where the defining factor between industry icons and those who disappear is the ability to adapt,” he said. The winning architecture, in his account, is a unified platform that lets businesses start with immediate use cases and scale to exabyte capacity without rebuilding, a claim the company supports by pointing to a path that runs from FlashBlade//S through to FlashBlade//EXA for GPU-cloud scale, with the KV Cache Accelerator optimising memory efficiency during inference and Portworx providing the container layer to run pipelines from edge to core.
That sequencing draws an endorsement from the infrastructure partner at the centre of it. Jason Hardy, Vice President of Storage Technology at NVIDIA, described the integration as the foundation organisations need to move from AI experimentation to full-production intelligence, language that mirrors Everpure’s own account of the journey. The two companies are also developing AI-native storage through NVIDIA STX, using NVIDIA Vera and the BlueField-4 storage processor to bring acceleration and intelligent data services closer to enterprise data as agentic deployments scale.
Running AI is harder than launching it
Preparing data and running a model still leaves the harder question of operating infrastructure intelligently once AI workloads are live, and the third stage extends the Enterprise Data Cloud to that operational layer. Everpure introduced updates to its Unified Data Plane, including Evergreen//One Overdrive, available in the third quarter of 2026, which grants a temporary performance boost of up to 25% above baseline to absorb traffic spikes without requiring a permanent subscription upgrade. Lherault tied this to the practical difficulty of acquiring hardware, explaining that organisations “can unlock that performance just for that period of time and then get back to your baseline” when a task such as month-end processing demands it.
Above that data plane sits the Intelligent Control Plane, which embeds AI into daily operations through natural language orchestration and predictive analysis. Copilot Workflow Execution, available in the second quarter of 2026, lets administrators plan, validate, and trigger operations across the global estate in natural language. Enhanced Cyber Anomaly Detection, also arriving in the second quarter, monitors telemetry to spot suspicious login patterns that individual arrays might miss in isolation. Workload Rebalance and Mobility, due in the fourth quarter of 2026, moves active workloads across the fleet without downtime, while Fusion Compliance and Agentic Triage, also a fourth-quarter delivery, detects configuration drift and uses agentic AI to suggest root causes for remediation.
Running alongside those operational tools is a bet on openness, one that concedes many organisations will want to drive Everpure’s infrastructure with their own software. The company released its Fusion MCP server and enhanced the Pure One server to support the Model Context Protocol, allowing customers to connect external AI and automation tools to Everpure systems without mastering proprietary APIs. Lherault expects this to grow more central as agentic automation of infrastructure itself takes hold. The aim, he said, is to show customers “how you can bring one of those tools and get it to talk to us and let us do the right thing, or let us give you the right information, without you having to build your understanding of our API into the tool.”
Governance has to travel with the data
What binds discovery, preparation, and operation into one story is a principle Everpure returns to at every stage, that governance must be attached to data rather than enforced by software sitting outside it. In the data primacy model the company describes, information is liberated from individual applications to become a shared system of record that is self-describing and carries its own meaning, logic, and privacy rules wherever it travels. Applications and agents read from and contribute to that record but do not own it, an inversion of the hierarchy that has governed enterprise IT for decades.
Lherault made the stakes concrete by pointing to an incident in which an AI model deleted an organisation’s data and backups. “It was not a malicious actor,” he said. “It was simply that the AI didn’t have the right context. It didn’t understand what was important.” That, in his telling, is why data quality has effectively become AI quality, since “your AI is only as good as the data that you feed it,” and a model lacking the right inputs “may make the wrong decision. It may hallucinate.” The same logic carries into the geography of governance, where the Fusion control plane lets organisations define fleets, regions, and availability zones, applying consistent global resiliency policies while accommodating divergent sovereignty rules. Pressed on whether that variation makes deployment unmanageable, Lherault held that protection standards should not weaken with location. “It’s not because your data lives in the UAE or in Europe that you shouldn’t ensure that data is protected in the same manner,” he said, while acknowledging the approach can generate more policies than an administrator might want.
The need to accommodate local nuance is what led him to treat customisation as a baseline rather than a feature. Beyond configuration itself, he noted, an organisation’s own processes might dictate that “before you configure it, this person needs to approve it,” or that a ticket must clear an escalation step first, which is why “customisation is table stakes here.” The wider argument finds external support in commissioned research the company cited, an IDC Global AI Readiness Survey in which 94% of IT leaders identified data quality as the determining factor in AI success. Matt Kimball, Vice President and Principal Analyst at Moor Insights and Strategy, put the constraint plainly. “The biggest bottleneck to AI adoption right now isn’t the software, it’s the plumbing,” he said, adding that placing data at the centre of enterprise strategy is how IT leaders can control runaway operational costs and accelerate rollouts.
Everpure is selling a destination, not products
The roadmap closes with the EDC Success Blueprint, a step-by-step methodology that begins with a readiness assessment to identify immediate infrastructure and security risks before mapping a path across 10 operational pillars from manual management toward an automated architecture. Lherault described it as a maturity model drawn from Everpure’s own internal experience and its work with customers, intended to help organisations advance without having to work out every step themselves.
The blueprint is also where the commercial logic beneath the architecture becomes visible. Everpure is not asking customers to buy Data Intelligence, Data Stream, or the control plane updates as discrete purchases so much as to commit to a direction of travel, with each release functioning as a stage on a journey the company has now mapped end to end. Lherault was explicit that the platform is designed to evolve as data sources, regulations, and use cases change. “Four years ago no one was deploying AI in production,” he said, arguing that constant change at every layer is exactly why “you do need to have that level of customisation” built in from the start. Whether enterprises accept that the path Everpure has drawn is the right one will determine how much of this roadmap they ultimately walk.