
How VAST Data quietly built an operating system for AI
When VAST Data first began using the phrase “AI Operating System,” the reaction was predictable. Operating systems sat at the centre of computing. They coordinated resources, absorbed failure, and imposed order on complexity. Storage systems, even highly advanced ones, traditionally sat at the edge, moving data in and out as quickly as possible. The two ideas rarely overlapped.
What made VAST’s claim unusual was not the language but the path that led to it. The company did not announce a bold new platform and then go looking for problems to justify it. Instead, over several years of building infrastructure for GPU-heavy environments, it found itself confronting the same breakdowns again and again. Systems slowed not because models were weak, but because data arrived late. Costs rose not because hardware underperformed, but because efficiency was sacrificed to keep up. Failures occurred not in the core technologies, but at the seams between them.
“This was not about trying to be ambitious,” said Jason Hammons, VP of Systems Engineering, International at VAST Data. “It was about dealing with the reality of how these systems behaved once they ran continuously, with real data and real cost pressure.”
He described deployments where everything appeared sound on paper, but fell apart once usage became constant. “The systems worked fine in bursts,” he said. “They struggled when they had to behave like infrastructure instead of experiments.”
By the time VAST formally unveiled VAST AIOS, the platform already behaved like an operating system in practice. The announcement did not introduce a new direction. It named one that had already taken shape.
Breaking the performance versus cost trade-off
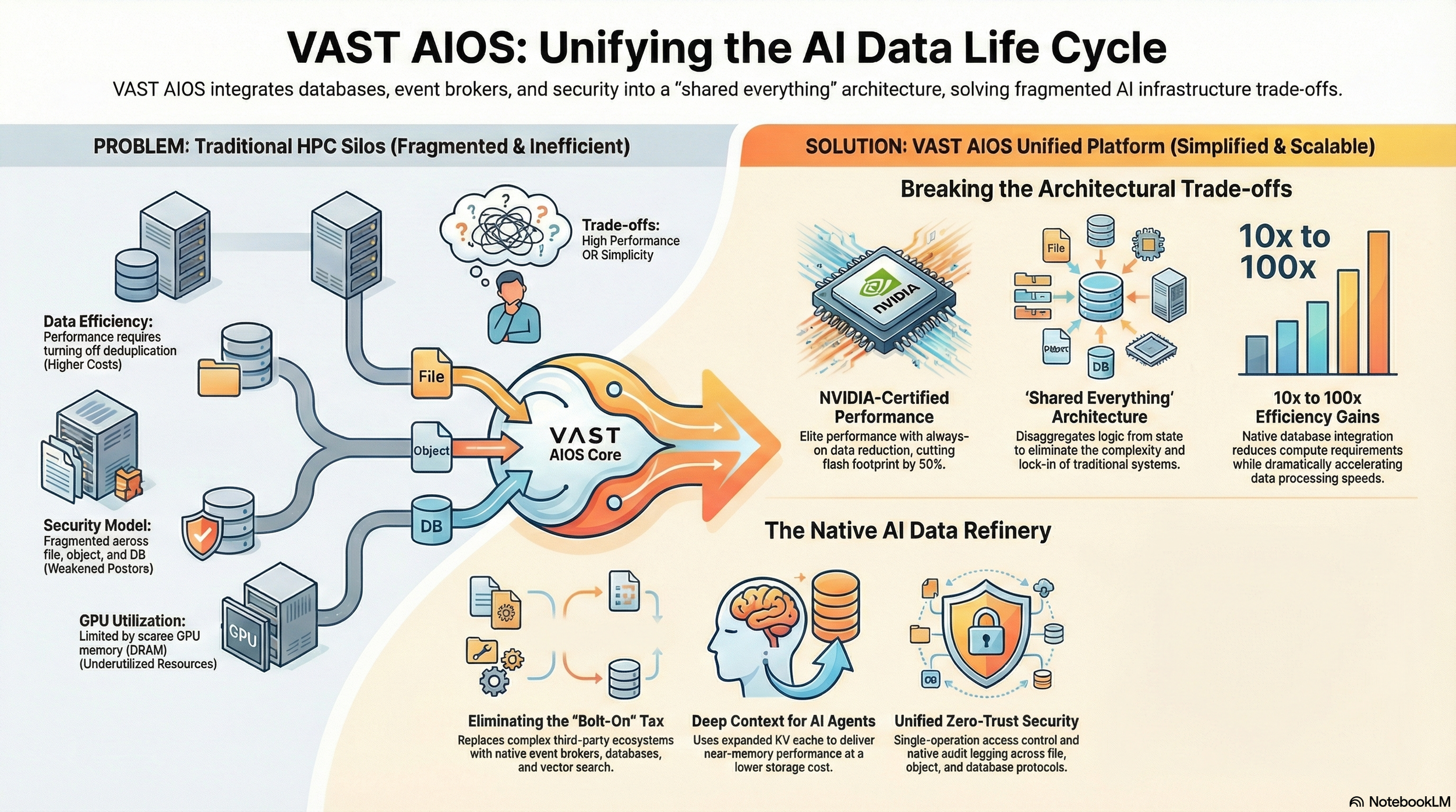
For decades, high-performance infrastructure had been built around a familiar compromise. Systems could be fast, or they could be efficient, but rarely both. Storage platforms designed to keep accelerators busy often required customers to disable compression, data reduction, or advanced durability features. Speed came at the cost of wasted capacity and higher operating expense.
VAST challenged that assumption early. Its “shared everything” architecture separated coordination and control from the physical layout of data, allowing performance to scale without forcing efficiency features to be switched off. Global data reduction and erasure coding remained active even under sustained, high-intensity workloads.
“We never accepted the idea that you had to turn efficiency off to go fast,” Hammons said. “That trade-off was a relic of older architectures.”
As NVIDIA GPUs became scarce and expensive assets rather than interchangeable components, those architectural decisions took on new weight. In GPU-dense environments, chasing throughput by overprovisioning storage or disabling reduction meant higher capital costs, higher power draw, and more fragile operations.
“At some point customers started doing the maths,” Hammons said. “They realised they were paying twice. Once for the GPUs, and again for all the waste around them.”
VAST’s ability to sustain NVIDIA-certified GPU performance while still reducing data globally changed that equation. Customers could keep more data online, train larger models, and delay hardware purchases without sacrificing speed. Performance and efficiency stopped being opposing goals.
The roadmap of AI OS
CoreWeave and the pressure of AI-first clouds
Those choices became more consequential with the rise of AI-first cloud providers such as CoreWeave. These environments were built around GPUs from the beginning. Storage, networking, and orchestration existed to serve accelerators, not the other way around.
In these settings, fragility was unacceptable. A few minutes of disruption could strand thousands of GPUs and translate directly into lost revenue.
“When you’re operating at that scale, five minutes of disruption isn’t a glitch,” Hammons said. “It’s a financial event.”
Working inside GPU-first clouds pushed VAST beyond the traditional expectations placed on storage systems. Customers were no longer asking only how fast data could be read or written. They were asking how quickly new data could be brought in, how reliably it could be accessed across tenants, and how often it had to be copied before it became useful.
“We started hearing the same thing from different customers,” Hammons said. “They didn’t want faster storage. They wanted fewer places for things to go wrong.”
SyncEngine and the reality of data that never stops arriving
The first clear signal of that shift came with the introduction of SyncEngine. The problem it addressed was not glamorous, but it was pervasive. Data did not arrive in neat batches anymore. It arrived continuously, and it changed constantly.
AI systems were being fed by live software logs, ongoing transactions, sensor readings, and traces of user activity. That information flowed in at all hours, and models were expected to stay current as it changed. In most AI stacks, keeping that flow aligned relied on external pipelines and event brokers. When those systems drifted, failures were subtle. Models worked with stale context. Results degraded quietly.
“What we kept seeing was teams spending enormous effort just keeping data consistent,” Hammons said. “That work didn’t make the AI better. It just kept the system from coming apart.”
SyncEngine embedded continuous synchronisation directly into the platform. Instead of treating ingestion as something that happened before storage, AIOS assumed data would always be arriving and always changing.
“We stopped thinking of data as something that lands and rests,” Hammons said. “In AI systems, data is alive.”
Information flowed into a single namespace, where it could be refined, indexed, and queried without being copied repeatedly between systems. This became the basis for VAST’s description of AIOS as a “data refinery,” a place where raw inputs were continuously shaped into something usable.
Naming the platform: VAST AIOS
When VAST announced VAST AIOS, it described the platform as a unified system bridging high-performance computing and enterprise cloud simplicity. The announcement connected capabilities that had been introduced gradually: continuous data intake, a native database, vectorisation, event handling, security controls, and execution logic, all operating on the same data foundation.
The motivation was practical. AI teams were assembling complex infrastructures made up of specialised products, each with its own operational model. At small scale, these systems could be managed. At larger scale, they became fragile.
“People hoped a collection of specialised tools would behave like a single system,” Hammons said. “That hope didn’t survive production.”
At that point, he said, the question shifted. “We were already being treated like the glue,” he said. “The honest question was whether we were willing to own that responsibility.”
Supporting agentic AI with memory, not repetition
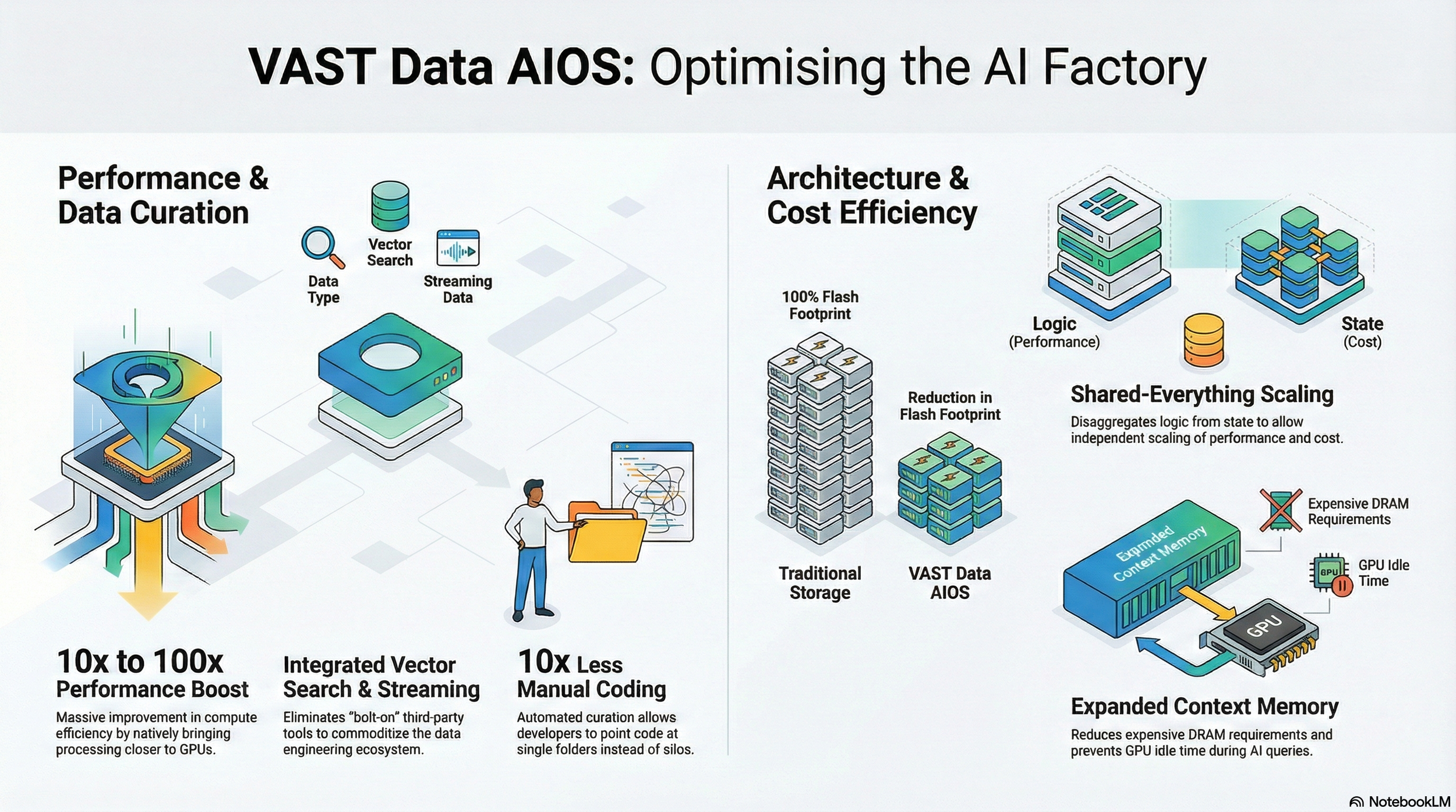
As AI systems evolved from static models into agents that reasoned over time, memory became a defining constraint. Agents relied on context built up across interactions. When that context was lost, systems rebuilt it from scratch, consuming GPU cycles customers paid for by the minute.
VAST’s collaboration with NVIDIA, announced through the NVIDIA Data Flywheel, addressed this inefficiency directly. The partnership extended key-value cache beyond GPU memory into shared storage while keeping access fast enough for inference and reasoning workloads.
“People underestimated how expensive forgetting was,” Hammons said. “Every time an agent had to rebuild context, it was burning compute for no gain.”
He described early agent deployments where most of the cost came not from reasoning, but from reloading state. “Once you see that, you stop thinking about memory as an optimisation,” he said. “You start thinking of it as survival.”
By allowing context to persist outside GPU memory, AIOS enabled agents to retain memory across sessions without relying solely on scarce accelerator or system memory.
AgentEngine and execution close to the data
The evolution continued with AgentEngine, which allowed pipelines, triggers, and agent workflows to execute directly within AIOS. Instead of exporting data to external compute services, logic ran where the data already lived.
This mattered because agentic systems magnified every weakness in infrastructure. Agents depended on fresh inputs, consistent state, and predictable execution.
“Agents didn’t hide problems,” Hammons said. “They exposed them immediately.”
With AgentEngine, the platform no longer only coordinated data. It hosted behaviour. Storage became a place where actions occurred, not just where information was kept. As AIOS expanded, governance became more important, not less. AI systems accessed data through multiple interfaces, including file and object protocols, each of which traditionally carried its own security rules.
VAST unified those controls at the platform level. In AIOS, permissions, encryption policies, and audit logs applied consistently regardless of how data was accessed.
“In most environments, security fragments over time,” Hammons said. “File rules drift one way, object rules drift another. We built it so the rules stayed attached to the data.”
For organisations operating under regulatory pressure, this reduced both complexity and risk.
Where responsibility finally settled
What emerged over time was not a single breakthrough, but a shift in where responsibility sat.
At first, VAST was asked to make storage fast enough to keep GPUs busy. Then it was asked to keep data available without forcing customers to choose between performance and efficiency. Later, it was asked to handle data that never stopped arriving, to preserve context that models could not afford to forget, and to enforce security rules that had to apply no matter how the data was accessed.
None of these requests arrived labelled as “build an operating system.” They arrived as operational problems, raised by customers running systems that no longer behaved like experiments.
“We didn’t set out to own more of the stack,” Hammons said. “But every time something failed, it failed at the boundaries between systems. And somebody had to take responsibility for that.”
AIOS was VAST’s response to that accumulation of responsibility. Not a platform designed in isolation, but one shaped by repeated exposure to where AI infrastructure actually broke. Not when a model was wrong, but when data moved too often, memory ran out, or security rules conflicted.
That was how VAST Data ended up building something it now calls an operating system. Not by trying to redefine AI, but by staying close enough to data infrastructure to see where it repeatedly failed for the AI generation.