
The Storage Wall: Why AI Is Breaking on Data, Not Compute
For most of the past two years, the enterprise AI conversation has been a compute conversation, dominated by GPU allocation, model size and the race to deploy. The shift now under way changes the centre of gravity entirely. By 2030, inference is expected to overtake training as the dominant AI workload, accounting for more than half of all AI compute and roughly 30 to 40% of total data centre demand, according to McKinsey’s data centre demand model, which puts inference capacity growth at a 35% compound annual rate against 22% for training. Each of those inference cycles does something training never did at the same intensity: it generates new data continuously, and that data has to be stored.
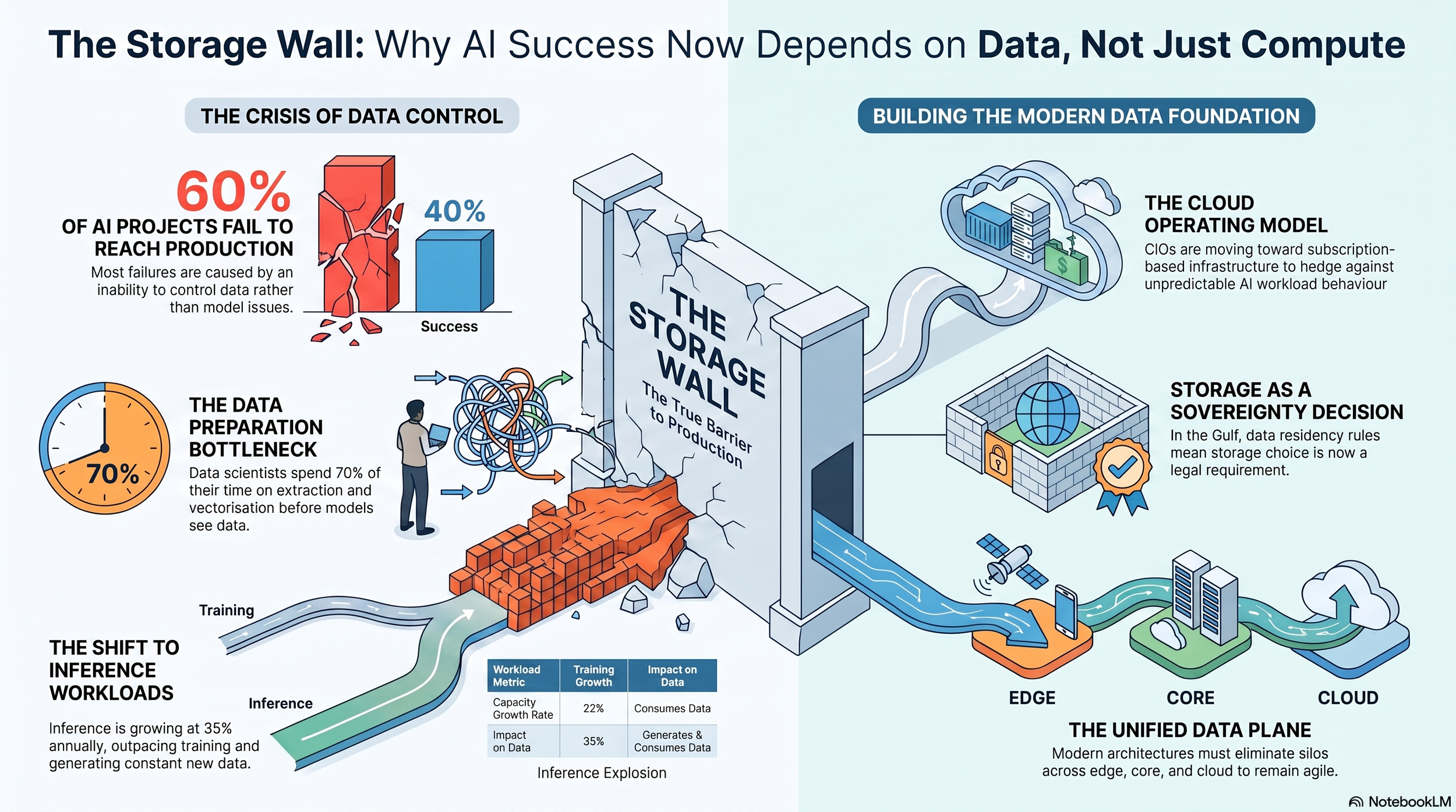
The executives building the infrastructure beneath those models describe a quieter and more consequential result of that shift. The thing most likely to sink an AI project is not a shortage of processing power but a failure to control the data feeding it. Omar Akar, Regional Vice President for the Middle East, Türkiye and Central Asia at Everpure, put the failure rate in stark terms. Almost 60% of AI projects never reach production, he explained, and the reason is rarely the model itself. “Most of the AI projects are failing not because customers are failing to adopt compute or to deploy AI software and models, but they’re failing because they cannot control their data,” Akar said. A similar share of projects, he added, are abandoned by CIOs who simply cannot trust what they would be feeding into the pipeline, asking whether the data carries personally identifiable or protected health information they cannot see.
That distrust has a measurable cost in time as well as outcomes. Akar pointed to the disproportionate effort that data preparation still demands before any intelligence can be extracted, noting that data scientists spend up to 70% of their time only on making sure data is ready to be recognised and consumed by AI, working through complex extraction, transformation and vectorisation before a model sees anything useful. The economic signal beneath that observation is now visible in vendor revenues. Figures from IDC put the worldwide external enterprise storage market at $9.2 Billion in the first quarter of 2026, growing 22.7% year on year, a sharp acceleration from the sub-4% annual growth seen through much of 2025, with the highest-end systems priced above $250,000 expanding by more than 60% as AI deployments pulled spending toward the top of the market.
What CIOs are now asking for has changed shape entirely
Mohit Pandey, Head of Sales for Middle East, Turkey and Africa at Seagate Technology, traced the same shift from the demand side. Eighteen months ago, he explained, most enterprise AI work sat in pilot mode, confined to testing and early experiments. Full-scale deployment has changed the nature of the requirement, forcing organisations to continuously access, move, retain and analyse vast volumes of data in real time. The scale of that retention pressure is borne out across the industry, with research from Omdia finding that three quarters of enterprises anticipate higher or significantly higher data growth rates over the coming two years than the previous twelve months, naming AI as the primary cause.
The question itself has been rewritten as a result. “The question has shifted from how much storage is needed to how to keep AI running cost-effectively,” Pandey said. Enterprises now want storage that runs continuously and lets them find, move and store large volumes of data without slowing performance or inflating cost. The deeper change, in his account, is that organisations have started to treat the value of data rather than merely its generation as the priority, wanting the information powering their systems to stay reachable, trustworthy and manageable over time, a concern that bites hardest in smart infrastructure, financial services and healthcare where AI produces new data continuously.
Pandey located that pressure firmly in the region. In April 2026 the UAE government announced plans to move 50% of public sector services to AI-driven autonomous systems within two years, one of the most ambitious commitments of its kind anywhere. “These AI systems do not just use data. They produce it constantly, make decisions based on it, and generate new data as a result,” Pandey said, describing a continuous cycle that places real strain on storage. His conclusion drew the thread tight. “AI is no longer just compute-intensive, it’s data-intensive, and how you store that data has become just as critical as how you process it,” he said.
The answer the market is converging on is the cloud operating model, not the cloud itself
If the problem is uncertainty, the response taking shape is a different way of buying infrastructure altogether. Akar described a recurring pattern in conversations with CIOs, where the word cloud surfaces for reasons that have nothing to do with moving workloads off premises. “They want a cloud operating model. They want to subscribe for an infrastructure that is delivered as a service with SLAs,” Akar said, so that they are not forced to overprovision against a future they cannot predict.
That unpredictability is not abstract. Enterprises have little history of procuring infrastructure for AI workloads and cannot forecast how those workloads will behave, a problem compounded by supply chain fragility and component price volatility, with IDC pointing to inflation running through SSD, HDD and DRAM pricing into system-level costs through 2026 and Deloitte projecting leading-edge wafer costs as much as 50% higher. Akar argued that the shift toward service-level-driven, pay-as-you-go infrastructure is in part a hedge, shielding buyers from both the behaviour of the AI and the turbulence of the components market beneath it.
For Akar, this is also why the storage vendor he represents recast itself, moving beyond selling capacity toward what he repeatedly called the data plane. “Data sits in the heart of everything,” he said, with applications, AI and even cyber security all revolving around it, so that when data breaks, everything built on top of it fails. The modern data plane, in his account, must be unified enough to eliminate silos across edge, core and cloud, agile enough to absorb surges, and capable of transforming data at the storage layer so that an AI application can actually recognise it.
Architecture is fragmenting by function, not consolidating around one model
On the question of how that data is physically stored, Pandey was clear that no single architecture wins. Customers are assembling combinations, he explained, each method doing what it does best. Object storage continues to gain ground for AI and analytics because it handles large-scale unstructured data efficiently, proving its worth in video surveillance, AI-powered analytics and large repositories, while file and block storage hold their place wherever low latency and high-performance processing matter most. That layering is reshaping the hardware mix beneath it, with IDC reporting that all-flash systems crossed half of all external storage revenue for the first time in early 2026 at $4.9 Billion, even as high-capacity hard drives remain the economic backbone of long-term retention in the cloud.
The result is a layered design philosophy in which performance-sensitive data stays close to compute and mass-capacity storage absorbs long-term retention. Those choices, Pandey noted, are governed by the balance between regulation, scalability, performance, power efficiency, resilience and total cost of ownership, with enterprises increasingly favouring architectures built for compliant and sustainable long-term growth over short-term speed. The customer demand, as he characterised it, reduces to two persistent questions: how to store more data without consuming more space, and how to do so without costs spiralling.
That economic pressure is what Seagate’s roadmap is built to answer, through the Mozaic platform built on HAMR technology, which Pandey said lets organisations fit significantly more data onto fewer drives in the same footprint using less energy, with the latest Mozaic 4+ platform supporting capacities of up to 44TB and each generation building on the last so enterprises can scale without overhauling what they already run. The regional stakes sharpen the point, with the UAE having committed to training 80,000 federal employees in agentic AI tools, making these pressures immediate rather than theoretical.
For the Gulf, the storage question is also a sovereignty question
Nowhere is the data-control argument more concrete than in the region both executives serve. Figures from Mordor Intelligence put the UAE data centre market on a path from roughly $1.48 Billion in 2025 toward $3.86 Billion by 2031, underpinned by sovereign-backed AI programmes, mandatory data-residency rules and hyperscale commitments that increasingly favour local, GPU-dense capacity. The Stargate UAE campus in Abu Dhabi, a partnership involving G42, OpenAI, Oracle, NVIDIA and SoftBank, is expected to bring its first 200MW online in 2026, with the country’s AI minister telling The National in January 2026 that the full build would cost more than $30 Billion, while Microsoft has separately committed a further $7.9 Billion to the country between 2026 and 2029. Each of these builds is, at bottom, a wager that data will be created and must be kept in-country.
That regulatory gravity gives Akar’s emphasis on compliance and residency a sharper edge in the Gulf than almost anywhere else. Updated data protection frameworks across financial, healthcare and government sectors are pushing sensitive workloads toward in-country storage and processing, and the sovereign cloud arrangements now being built, such as Microsoft’s in-country integration through Core42, exist precisely so that regulated data can stay within national borders while still drawing on global redundancy. The storage decision and the sovereignty decision, in this market, have become the same decision.
Trust, compliance and sovereignty are becoming the layers that decide everything else
Looking ahead, Akar set out the layers he believes every enterprise must now account for, and the list reaches well past storage. Beyond a unified data plane governed by service-level agreements, he placed data protection and cyber resilience, then trust, defined as the contextual visibility to understand exactly what data is being handled and to apply automatic exclusions that prevent a breach when data is fed into a model.
Compliance forms the next layer, and Akar was emphatic about where it now ranks, particularly on questions of where data physically resides. Enterprises need to track and map data continuously to satisfy residency and sovereignty requirements, he explained, before it can be transformed and stored in the high-dimensional vector databases that make semantic search and retrieval-augmented generation possible.
Only once data is unified, protected, compliant and recognisable, in his account, can an organisation begin to operationalise AI by building the intelligent hub that manages models, versions and GPU clusters at scale. Both executives, approaching from opposite ends of the same market, arrive at one conclusion that reorders a decade of assumptions: storage used to be an afterthought in AI planning, and the organisations now seeing the most from their AI investments are precisely those that no longer treat it as one.